Warning: This article related to ansible after version
2.5.0. The behaviour of tags in ansible has changed over the last few releases.
In the simple case, tags in ansible work mostly as expected. However once you reach a sufficient level of complexity, you will find tags either running, or not running in a confusing manner unless you apply them suitably. In particular understanding how ansible propagates tags down into included tasks/roles is important.
A good example of a reasonably complex ansible playbook, is the test role from the Lime Pepper wordpress ansible role
Here, ansible is going to load several other roles (mysql and apache), before even starting on the wordpress role. The whole thing takes a few minutes to run (even after the 1st converge, when the packages have been installed) which is something of a PITA if you just want to debug a few modules somewhere deep inside.
- import_role:
name: limepepper.mysql
- import_role:
name: limepepper.apache
vars:
apache_opts:
- php/mod_php
- ssl/mod_ssl
- rewrite
- name: import the role limepepper.wordpress in test.yml playbook
import_role:
name: limepepper.wordpress
# name: '{{ playbook_dir }}/..'So a key use of tags is to reduce the runtime, and total list of modules processed to just the ones you are interested in.
Timing your ansible runs
It’s useful to know exactly how long each run took, and in particular how long each module took to exectute.
For reporting the overall time of the ansible run ansible ships with a timer
callback, which can be enabled in your ansible.cfg file like so;
[defaults]
...
callback_whitelist = timerThis results in a summary of the overall time at the end of run report like so;
PLAY RECAP ***************************************************************
debian-9 : ok=17 changed=0 unreachable=0 failed=0
Playbook run took 0 days, 0 hours, 2 minutes, 20 secondsFor timing information for each module as it is processed, I am currently using the ARA callback. Which produces per module timing data in a nice webpage like so;

Another use of ARA is that it will show you which tags were actually applied to a module at runtime. (tags are shown by hovering over the task in the tasks view);
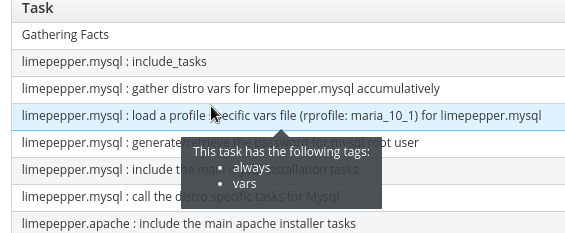
Tags on imports and includes
So the next thing to consider is how import_role and include_role treat
tags. Let’s say we make a call like so;
$ ansible-playbook mysql-playbook-test.yml --tags mysql
import_role
If you import the role like so, the tasks contained will be processed, and each included task will be considered on it’s own tags.
- import_role:
name: limepepper.mysql… tasks in limepepper.mysql/tasks/main.yml
- name: install mysql packages
package:
- mysqld-server
tags: mysqlthe tasks are run
TASK [limepepper.mysql : nstall mysql packages] **************
ok: [debian-9] => changed=false
cache_update_time: 1537094017
cache_updated: false
...include_role
However if you include the role, then the tasks will only be considered, if
the include_role itself, has a relevant tag;
- include_role:
name: limepepper.mysql
tags: mysqlI found this very confusing at first.
So the aim is to be able to run some task in the mysql role, without running everything in the role. So lets say we have these 2 tasks, and we only want to run one of them, we can do;
- name: install mysql packages
package:
- mysqld-server
tags:
- mysql
- run-me
- name: install other mysql packages
package:
- mysql-tools
tags:
- mysql
- dont-run-meand set the include_role like so;
- include_role:
name: limepepper.mysql
tags:
- mysql
- run-me
- dont-run-mewe can call ansible like so, to only run the run-me tags;
$ ansible-playbook mysql-playbook-test.yml --tags run-me
However that is obviously very verbose, and requires explicit tagging at lots of levels to achieve any decent granularity.
A simpler way to achive the same output, is to use the always tag on the
include, and use a block in the include tasks file like so;
- include_role:
name: limepepper.mysql
tags: [always] - tags: [mysql]
block:
- name: install mysql packages
package:
- mysqld-server
tags: [run-me]
- name: install other mysql packages
package:
- mysql-tools
tags: [dont-run-me]This tactic also works with import_role. So taking the example at the top;
- import_role:
name: limepepper.mysql
- import_role:
name: limepepper.apache
- import_role:
name: limepepper.wordpress$ ansible-playbook mysql-playbook-test.yml
would run all the roles and tasks
$ ansible-playbook mysql-playbook-test.yml --tags mysql
would just run the just the mysql role tasks
$ ansible-playbook mysql-playbook-test.yml --tags run-me
would just run the tasks tagged run-me whereever they exist anywhere in any
role
Summary
1). To make include_role and include_tasks act like static imports, tag the
include itself with always;
# playbooks/limepepper.wordpress/my-playbook.yml
- include_role:
name: limepepper.mysql
tags: [always]2). To be able to run tasks on a fine level of granualarity, the basic idea is to have 2 layers of tagging.
The first is to tag tasks in a role with the name of the role. See here for an example of doing that in a production role.
---
# tasks/main.yml
- tags: [ wordpress, wordpress-cli ]
become: yes
block:
- debug:
msg: this will run if wordpress tags is supplied to --tags3). and the second level, is for very granualar tagging, like so;
---
- tags: [ wordpress, wordpress-cli ]
become: yes
block:
- debug:
msg: |
this will run with no tags, wordpress tagged, or bootstrap tags
or any combination of the above
tags: [ bootstrap ]